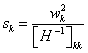2.8.8. Topology Optimization by Pruning Algorithms
The oldest
and very popular approach to topology optimization of neural networks
is based on destructive pruning algorithms [59],[109],[122]-[124].
These algorithms start with a trained fully connected neural network,
remove certain network elements and then retrain the network. The steps of removing
and retraining are repeated until a certain stopping criterion is fulfilled.
Besides of the algorithm "Skeletonization" [134],
only links are considered as candidates to be removed. Neurons are automatically
removed, if all corresponding input or output links have been removed. In this
work the two pruning algorithms "Optimal Brain Surgeon" and "Magnitude
Based Pruning" are used, which were identified as most promising pruning
methods for sensor data in a comparison [28]. A combination
of both algorithms can be found in [153].
Magnitude Based Pruning
The Magnitude Based Pruning (MP) is the simplest approach among the pruning
algorithms, which removes the links with the smallest weights. This approach
originates in the linear regression, as the variables with the smallest regression
coefficients of a linear regression are least important. Yet, Despagne et al.
demonstrated that for data sets with both, linear and nonlinear relationships,
this assumption is not valid as primarily links of linear variables are removed
[135].
On the other hand, it was shown in [28],[136]
that this simple and very fast algorithm performs as well as the other algorithms
as long as not too many links are removed.
Optimal Brain Surgeon The Optimal Brain Surgeon (OBS) algorithm [137]
estimates the increase of the training error when a link is deleted. Then the
links with the smallest increase, which is also called saliency, are deleted.
To determine the saliencies, the changes of the cost function associated
with a perturbation of the weight matrix W
has to be evaluated. The term is approximated by a second-order Taylor
series expansion:
(20)
As the
training is stopped when the neural network has converged to a minimum, the
first term can be considered as being zero. The second and third term are the
so-called Hessian Matrix H, whereby
the Optimal Brain Damage algorithm [138] neglects the third term resulting
in faster yet less reliable pruning results [28]. The
saliency of a weight k is then calculated as
(21)
Discussion Although the pruning algorithms have been applied in
several fields of chemistry and analytics [55],[109],[139]-[141],[153] the general application of these algorithms
is controversially discussed in literature. In congruence with the theory that
pruned sparse neural networks should generalize better, improved predictions
were found in references [28],[142],[143]
whereas a deterioration of the prediction ability was found in references [136],[144].
Another problem of the pruning algorithms is the need of a reference network
for the removal of the network elements. This reference network has to be designed
by the user and the final optimal network found by the algorithm cannot be more
complex than this reference network. This means that the "solution"
is biased by the choice of the user for the reference network as the pruning
algorithms are highly sensitive to local minima of the error surface ending
up in completely different network topologies and different variables selected
for different reference networks.