Also,
the parallel growing neural network framework introduced in chapter
8 was applied to the data with 500 parallel runs of the growing neural networks
for each analyte. The ranking of the variables, which is combined for all analytes
similar to section 9.1.2, is shown in figure
66. The second step of the algorithm (20-fold random subsampling sets) stopped
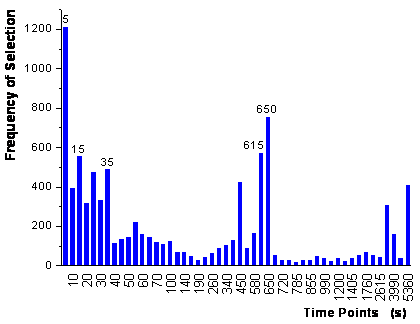
after the addition of 5 variables, which are labeled in figure
66. Compared with the variable selection by the GA framework, the selection
by the parallel growing network framework looks similar, but not identical.
Instead of the signal at 20 s the time point 35 s is used (variation of ethanol
and 1-propanol) and instead of the time point 55 s the signal at 650 s is used
(main variation of 1-propanol). According to table
6, the corresponding optimized neural networks (4 hidden neurons and 1 output
neuron) showed the best predictions of all methods used for this data set.
figure 66:
Frequency of the variables selected in the first step of the parallel growing
neural network framework
The randomization
test (200 parallel runs of the growing nets) demonstrates that the parallel
growing neural network framework is highly reproducible with the selection of
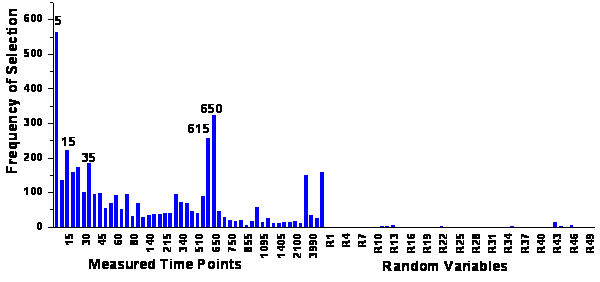
the same 5 variables (see figure 67). When comparing
figure 67 with figure
65, it is obvious that the growing neural nets are less subject to selecting
random variables due to chance correlation than the genetic algorithm.
figure 67: Ranking of the variables
for 50 time points and for 50 additional random variables.