Similar
to section 6.9, a compression of the input space for
the data analysis by neural networks was performed by a principal component
analysis. The optimal number of 19 principal components was determined by the
minimum crossvalidation error of the calibration data. The predictions of the
calibration data are promising whereas the predictions of the validation data
are significantly worse (see table 6).
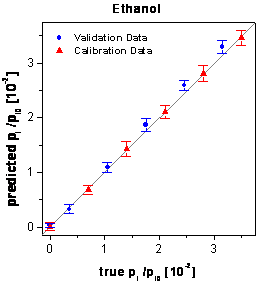
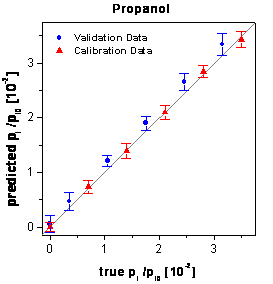
The true-predicted plots (figure 68) demonstrate
that the predictions of the validation data are biased towards too high predictions.
The bias
can be explained by the different amount of noise of the validation and calibration
data sets in combination with the nonlinearities in the data sets (see discussion
in section 6.9): The linear PCA projection spreads the
nonlinearities over many principal components resulting in the selection of
the high number of 19 components by the minimum crossvalidation error criterion.
On the other hand, the typical noise of the calibration data set is included
in theses components. Thus, most of these components contain a combination of
important information about the model and information about noise. As the validation
data set was recorded by averaging two measurements, the noise is significantly
reduced resulting in a changed data structure and thus a changed projection
by the PCA causing the significant bias of prediction.
figure 68: Predictions of the
calibration and validation data by PCA-NN.