For all
data sets, several calibrations using the corresponding calibration data set
were performed, whereby the predictions of the external validation data are
summarized in table 8. First of all, calibrations
were performed using all time channels of the SPR setup and all smoothed time
channels of the 3 sensors of the RIfS array setup (1st and 5th
row of table 8). Then the same data sets were used
for the parallel growing neural network framework (2nd and 6th
row). It is obvious that for both setups the framework significantly improves
the calibration of all analytes. The SPR setup performs better on the calibration
of methanol and ethanol and the RIfS array with 3 sensors performs better on
the calibration of 1-propanol and 1-butanol whereby the overall mean predictions
of the RIfS array with 3 sensors are better. The predictions of the calibration
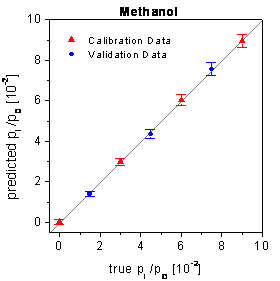
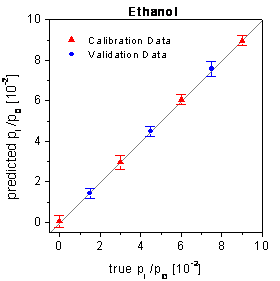
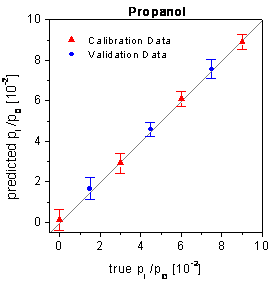
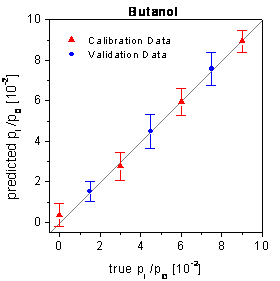
and the validation data are shown in figure 73 for
the SPR setup (the neural networks had been optimized by the framework). For
both setups, the framework selected time points spread over all sensors and
over the complete process of sorption and desorption. An interesting point is
the restriction of the available time points to a certain shorter time interval,
which would correspond to faster measurements. The restriction of the data analysis
for the SPR measurements to 240 seconds (120 seconds of sorption and 120 seconds
of desorption) instead of 930 seconds hardly had a negative impact on the calibration,
whereas the restriction to 120 seconds of sorption significantly decreased the
calibration performance. Decreasing the analysis time of the RIfS array from
3470 seconds to 640 seconds deteriorated the prediction performance less than
decreasing the analysis time from 640 seconds to 236 seconds, which corresponds
to the sorption process only. This means that for both setups the measurement
time can be drastically reduced without too high an impact on the prediction
performance. Yet, it is important to consider not only the sorption process
but also the beginning of the desorption process. This is consistent with most
variable selections by the frameworks in the previous sections (8.4.1,
9.1.2, 9.2.3, 9.2.4
and 9.3.2) with only variables selected directly after
the beginning of exposure to analyte and directly after the end of exposure
to analyte (see also discussion in section 10.3).
figure 73:
True-predicted plots of the SPR setup using the optimized networks and the time
points of the complete measurement time.
The effect
of smoothing the sensor signals of the RIfS array was investigated for the singles
sensor responses of the two Makrolon layers. Similar to section
9.3.2, the thinner 95 nm layer benefited from the smoothing whereas the
thicker 165 nm layer was adversely affected by smoothing. The single sensor
predictions of the RIfS array are all worse than the single sensor predictions
of the SPR setup even with nearly 4 times longer measurement times of the RIfS
setup. As already discussed in section 9.3.1,
the RIfS setup, which primarily detects changes of the thickness d of the sensitive layer [260],
is more affected by Makrolon mainly changing the refractive index n when exposed to analyte, than the SPR setup,
which mainly detects changes of the refractive index n. Nevertheless, the comparison with the
static sensor evaluation (only the highest sensor signals of each sensor), which
is an undetermined system with 3 sensors for 4 analytes and which consequently
shows very high prediction errors, demonstrates the potential of the time-resolved
measurements also for the RIfS principle with many possibilities for further
developments (last row of table 8).
Method
Meth.
Eth.
Prop.
But.
Mean
SPR, unoptimized
9.6
11.0
16.4
19.0
14.0
SPR, optimized
5.8
6.5
10.2
16.0
9.6
SPR, optimized,
<240 s
5.4
4.5
12.7
20.4
10.7
SPR, optimized,
<120 s
13.5
12.2
15.8
20.9
15.6
RIfS, 95 + 165 +
PUT, unopt., smoothed
15.1
13.6
12.9
12.1
13.4
RIfS, 95 + 165 +
PUT, opt., smoothed
10.1
10.0
8.2
6.5
7.3
RIfS, 95 + 165 +
PUT, opt., sm., < 640 s
9.9
10.0
9.7
7.2
9.2
RIfS, 95 + 165 +
PUT, opt., sm., < 236 s
14.1
12.8
12.2
9.1
12.1
RIfS, 95
optimized, raw
12.6
11.7
14.2
20.3
14.7
RIfS, 95
optimized, smoothed
12.5
10.5
12.6
18.1
13.4
RIfS, 165
optimized, raw
19.6
17.6
13.9
15.5
16.7
RIfS, 165
optimized, smoothed
22.1
19.6
15.8
18.1
18.9
RIfS, 95 + 165 +
PUT, 1 static time point
43.8
43.9
41.1
22.5
37.8
table 8: Relative RMSE of
the validation data in % for the 4 analytes and the mean using different data
analysis methods, different setups and different constraints of time points
(95 = 95 nm Makrolon layer, 165 = 165 nm Makrolon layer, PUT = PUT layer; optimized
= growing neural network framework, unoptimized = all time channels, smoothed
/ raw sensor signals).